This is the multi-page printable view of this section. Click here to print.
博客
2024 开源之夏结束,HoraeDB 参与同学获得最具潜力奖!
开源之夏是由中国科学院软件研究所“开源软件供应链点亮计划”发起并长期支持的一项暑期开源活动,旨在鼓励在校学生积极参与开源软件的开发维护,培养和发掘更多优秀的开发者,促进优秀开源软件社区的蓬勃发展,助力开源软件供应链建设。
2024 年 Apache HoraeDB 共有两个项目匹配成功,并且全都顺利完成!
单机版 WAL 实现
WAL 是保证数据可靠性的重要组件,在之前的实现中,采用的是 RocksDB 引擎作为 WAL 的实现,RocksDB 本身是个复杂的组件,基于它来实现 WAL 会有以下问题:
- 编译困难,在 HoraeDB 开发者邮件列表,编译 RocksDB 失败的邮件经常出现
- RocksDB 自身作为一个完整的 LSM 引擎,本身会有 Compaction、Memtable 等组件,这些组件会带来额外性能损耗,而且调优比较复杂 基于此,我们想设计一个基于本地磁盘的 WAL 实现,去掉 RocksDB 这个依赖。
顾龙同学在实现本地 WAL 的过程中,展现了其较强的代码功底,主要体现在如下几点:
- 能够独立设计出项目的基本架构
- 较强的代码阅读能力,能够在已有项目的基础上,完成新功能的开发
- 在性能压测阶段,能够找到正确的方式来发现系统的瓶颈,能提出解决方案,最终达到性能要求

远端合并
Compaction offloading 是数据库在大规模部署的场景下,很有必要支持的一个能力,否则会和对实时性具有高要求的读写节点竞争有限的资源,大幅影响服务稳定性。而要 compaction 模块是 HoraeDB 的核心模块之一,要理解其逻辑,并在此之上进行较大改动,从而支持 compaction offloading 能力是很有挑战性。
苏逸钒同学不但在短时间内就深入了解了 HoraeDB compaction 模块的运行逻辑,而且能通过调研 HBase 等成熟开源项目的类似能力,快速提出在 HoraeDB 支持 compaction offloading 能力的合理方案,并在后续独立实现了方案,展现了其不俗的技术基础、工程能力和学习能力。
更难能可贵的是,苏逸钒同学在此之外,还主动熟悉了 HoraeDB 的核心上游项目 Datafusion,并且快速融入了 Datafusion 社区,因此获得最具潜力奖 🏅

加入我们
通过开源之夏,我们见证了众多优秀学生在开源社区的成长。希望在明年的开源之夏中,能够见到更多优秀的学生开发者在开源的海洋中扬帆起航。如果你也对开源充满热情,渴望在技术的道路上获得更多的历练与成长,我们期待与你相遇!
欢迎 Apache HoraeDB 新晋 Committer: Neo Chen
各位开发者们,
今天很高兴宣布,HoraeDB 社区新增了一个 committer:Neo Chen,他之前的贡献得到 HoraeDB PPMC 的一致认可,并于 2024-12-22 投票成为 committer,感谢他一直以来的贡献。下面是他的贡献记录:
https://github.com/apache/horaedb/commits/main/?author=zealchen
需要明确一点,成为 committer 并不需要额外做什么,主要是方便开发者后续可以更便利(有仓库写权限)地参与社区贡献。
最后,再次感谢 Neo Chen 一直以来对社区的付出,衷心希望他能继续贡献,共同见证社区的成长。
欢迎更多感兴趣的朋友加入我们的社区,与我们近距离交流。
HoraeDB Python 客户端 2.0.0 版本发布
大家好: Apache HoraeDB(孵化中)社区很高兴地宣布 Python 客户端 v2.0.0 已经发布,这是进入 Apache 孵化器后的第一个版本!具体使用可以参考文档,下面是发布日志:
What’s Changed
- fix: wrong timestamp in example by @ShiKaiWi in https://github.com/apache/horaedb-client-py/pull/35
- chore: rename ceresdb to horaedb by @chunshao90 in https://github.com/apache/horaedb-client-py/pull/36
- chore: upgrade rust client by @ShiKaiWi in https://github.com/apache/horaedb-client-py/pull/37
- chore: add asf yaml by @chunshao90 in https://github.com/apache/horaedb-client-py/pull/38
- chore: add incubating notice by @baojinri in https://github.com/apache/horaedb-client-py/pull/40
- feat: support basic auth by @jiacai2050 in https://github.com/apache/horaedb-client-py/pull/41
- docs: update README.md by @baojinri in https://github.com/apache/horaedb-client-py/pull/43
- chore: fix asf header by @jiacai2050 in https://github.com/apache/horaedb-client-py/pull/44
New Contributors
- @chunshao90 made their first contribution in https://github.com/apache/horaedb-client-py/pull/36
- @baojinri made their first contribution in https://github.com/apache/horaedb-client-py/pull/40
- @jiacai2050 made their first contribution in https://github.com/apache/horaedb-client-py/pull/41
Full Changelog: https://github.com/apache/horaedb-client-py/compare/v1.0.0...v2.0.0
加入我们
我们希望发展我们的社区,并欢迎新的贡献者。如果您有兴趣为 HoraeDB 做出贡献,请在邮件列表或 GitHub 上联系我们。我们很乐意帮助您开始。
2024 年 ApacheCon 北美之旅的收获与感悟
Apache HoraeDB 是 2023-12-11 加入 Apache 孵化器,由此拉开了我在 Apache 社区的成长探索之旅。作为一个历史悠久的基金会,Apache 旗下的软件可谓家喻户晓:Hadoop、Spark、Kafka 等等。 在这次 2024 年的 ApacheCon 北美大会上,我有幸代表 HoraeDB 社区参加,终于有机会来近距离和来自世界各地的 Apache 项目的 PMC 们交流。这次经历不仅让我深入理解了 Apache 项目的核心价值与贡献,还深刻认识到开源社区如何驱动技术创新、促进开发者之间的协作与分享。
这次大会在丹佛的君悦大酒店举行,为期四天(2024-10-07 ~ 10),讨论涉及搜索、大数据、物联网、社区等多个方面,从现场来看,讲师比嘉宾还要多,除了 Keynote 分享是在一个大会场进行,其他的场子均在一个小房间里,每个房间外会有一个电子屏展示今日的议题。全部日程见官网 Sessions Schedule。

文化差异
在介绍具体议题之前,我想先简单介绍下与会过程中感受到的中美间的文化差异,以飨读者。
和国内会议类似,第一天议程结束后有个晚宴(event reception),但这个晚宴可不“简单”,不是传统的晚宴,社交属性更重些。场地内会有几个比较高的圆桌,大家在旁边拿完东西后就可以找感兴趣的人开聊。对于第一次参见这种会议的我来说,其实有是些蒙的,和一同去的同事默默站在一角观望可以插入的场子,但看着周边人群在慷慨激昂的谈论时,发现自己不能很轻松地加入:一是语言问题;二就是文化差异。
在转了几圈后,发现几个国人面孔,通过沟通知道了他们都来自苹果公司,苹果是这次的大赞助商,所以他们大概来了四五十人!只不过组比较多,所以很多人也是第一次见面。听他们说这种聚会形式在美国挺常见的,他们虽然在美已经多年,语言早已不再是什么问题,但碍于文化差异,他们也不能很轻松的融入进去。
通过交流,了解到苹果公司内很多基建都是基于 Apache 的项目构建,而且最近几年他们在开源上的力度也越来越大,印象较深的就是 Swift 语言,其中一个女士貌似是 Swift 的 team member,她看到我穿的是带有 Rust logo 的衣服,就建议我尝试下 Swift,这两个语言设计理念类似,但 Swift 更简单,而且为了避免苹果一家独大,他们已经把 Swift 迁移到独立的 GitHub 组织上去。此外,Swift 也不仅仅是苹果平台的特定语言,他们也花了很多精力来保证 Swift 在 Linux/Windows 上也能完美的运行。
可以想到,苹果把 Swift 定位为通用语言,既可以为苹果生态服务,也是更长远的战略布局。通过通用化,苹果能够扩大 Swift 的生态影响力,吸引更多开发者进入其体系,同时为跨平台的未来做好准备。现在想想,华为的仓颉语言 也是类似思路。打造生态前期投入肯定是巨大的,需要长期投入和耐心的过程,但对大企业来说,这种投入实际上是一种战略性资源配置,目的就是建立长期的技术竞争力。
在会场中,我也有幸见到了 Database Internals 一书的作者 Alex Petrov(目前在苹果工作),给他简单介绍了下 HoraeDB,他的本能反应就是 Very cool!在国内我还真没遇到类似回答。
演讲介绍
接下来就介绍几个笔者印象比较深的演讲,由于没有演讲时的 PPT,因此下面的介绍是我根据印象中的关键词搜索整理的,仅供大家参考。
Optimizing Apache HoraeDB for High-Cardinality Metrics at AntGroup
这是我带来的演讲,介绍了 HoraeDB 重点解决的问题,以及对应思路和方法。核心一点就是通过 AP 领域的思路(剪枝、BRIN)来解决高基数时间线的问题,细节可以参考本次分享的PPT。
现在的版本我们其实也遇到了些新问题。目前的引擎在以时序分析为主的场景来说运行的会比较好,但在传统的时序告警领域工作的并不是很好,主要在于两点:
- 一次查询的代价太大,在查询引擎中采用了通用的 Arrow 格式,反而导致丢失了针对时序特点的优化
- 采用表作为基本数据组织方式过于严格,时序本来是一种弱 Schema 的场景,而提前定义好固定模式的表显然是一种“退步”,另外表作为资源管理单位,也限制了单机能够承载的表数量。
因此在后续的版本中,我们吸取了现在引擎(即目前的 Analytic Engine)的教训,打算重新设计一种引擎(称为:Metric Engine)来解决高基数的问题。
新引擎正在紧锣密鼓的开发中,感兴趣的读者可以参考这里的 RFC 来了解设计思路。在后续的版本发布时,我们也会重点强调新引擎的开发进度。
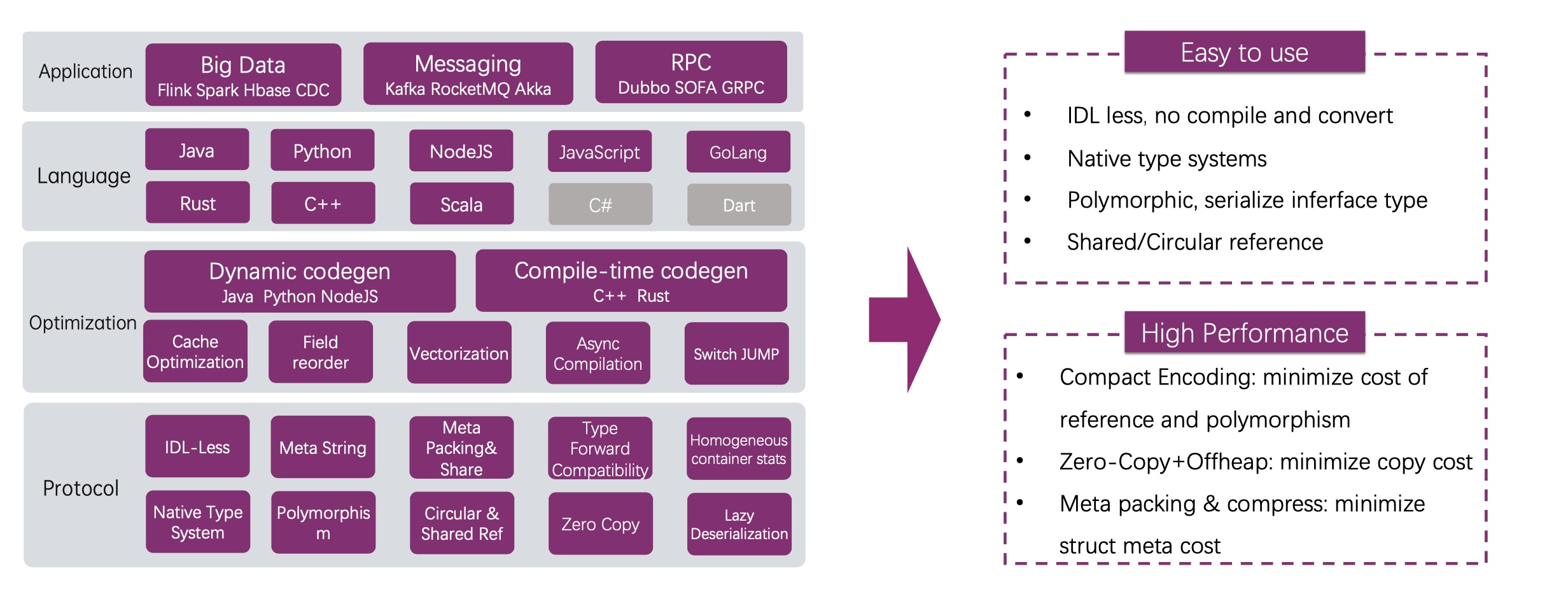
Blazingly-Fast: Introduction to Apache Fury Serialization
演讲者是 Fury 项目的发起者 Shawn Yang,也是我的同事。如标题所说,Fury 定位的就是高效的序列化,已经在诸多系统中被使用(参见:Who is Using Apache Fury?),并取得显著提升。
一直以为序列化是个已经解决的问题,了解了 Fury 后才了解到这个领域的问题。举个简单的例子,对于常见的 Protobuf 来说, 在序列化一个数组的 Message 时,Message 的元数据会序列化多次,但如果应用层能够保证每个字段都不会缺失,那么这样就是有些浪费的,在 Fury 中就可以 schema consistent 这种模式来避免这种冗余。
Making Apache Kafka even faster and more scalable
Kafka 是一种高吞吐量的分布式流处理平台,尽管十分流行,但近些年随着使用场景的复杂,挑战者也不少,比如:
- 主打云原生的 Pulsar
- 金融级可靠性的 RocketMQ
- 强调低延迟的 RabbitMQ
这个议题的嘉宾来自 Instaclustr,提供托管的 Kafka 服务。他主要从两方面来讲述了对 Kafka 的改进:
- 使用 KRaft 替换 ZooKeeper,这个主要是为扩大分区数考虑,分区是 Kafka 里很重要一概念,是进行并发读写的基本单位,在嘉宾的测试中,基于 ZK 的版本最高可以达到八万个分区,而基于 KRaft 的版本可以达到近两百万的分区。细节可以参考:Kafka Control Plane: ZooKeeper, KRaft, and Managing Data。
- 分层存储(Tiered storage),冷热数据分离的标配,通过将访问低频的数据移动到 S3 上可以显著降低成本。KIP-405 最早在 2020 年就提出来了,3.6.1(2023) 发布到期访问版,3.8.0(2024) 发布 V1 正式版。
Tomcat 11 and Jakarta EE 11
Tomcat 是 Java Web 开发领域的一个经典开源项目,不仅仅是一个 Web 服务器和 Servlet 容器,更承载了许多开发者的回忆。虽然不写 Java 很多年了,但看着到这个项目还是挺亲切的,毕竟谁能不喜欢这只 Tom 猫呢?

这个议题里分享了最新的 11 版本中的特性:
- 最小支持的 Java 版本升级到 17
- 通过 FFM 支持与 OpenSSL 集成(需要 Java 22+)
- 增强基于虚拟线程的执行器(VirtualThreadExecutor)
- 日志增加 JSON 输出格式
- 移除以下功能
- Security Manager support
- 32-bit Windows support
- HTTP/2 Server push support
都是些与时俱进的功能,记得在很早就看过 HTTP2 的 Push 功能有些鸡肋,这个案例说明了一个重要的原则:有时看起来很好的技术特性,在实际应用中可能并不如预期。
Cassandra
Cassandra 议题这次会议上非常多,印象中有一个房间一整天的议题都是与之相关,没想过 Cassandra 能有这么流行,甚至还有一个 BYOT(Bring Your Own Topic) 环节,来让大家交流 Cassandra 使用心得。下面是几个重量的议题:
- The Road to 20 Terabytes per Node: Overcoming Cassandra’s Storage Density Challenges
- Apache Cassandra as a Transactional Database
- Lessons from (Probably) the World’s Largest Kafka and Cassandra Migration
遗憾的是,由于演讲者说话速度较快,再加上我对 Cassandra 了解较少,大部分议题未能完全领会,只能课下再下功夫了解了。但尽管如此,还是对一个议题印象颇深,是一个由满脸白胡子的嘉宾分享的关于在查询中实现分页的演讲,很工程的一个问题,演讲者围绕其对性能的影响、潜在的误用风险等多个维度进行了详尽剖析,展现出深厚的专业功底和匠人精神。

ODBC takes an Arrow to the knee: ADBC
Apache Arrow 是一个跨语言的内存数据处理框架,通过标准化内存中的列式数据表示来实现高效的数据交换和处理。 和 JDBC 类似,ADBC 是基于 Arrow 的、供应商中立的 API,方便用户高效查询支持 Arrow 的数据库,比如 DuckDB,就有 38 倍的提升!
其他
Apache YuniKorn,云原生时代的资源调度器,和现场一个苹果的朋友聊,他们就在用它来调度他们 AI 相关的任务!
PRQL(Pipelined Relational Query Language),另一个查询语言,相比 SQL 功能更强大、简洁。示例:
1 2 3 4 5 6 7from tracks filter artist == "Bob Marley" # Each line transforms the previous result aggregate { # `aggregate` reduces each column to a value plays = sum plays, longest = max length, shortest = min length, # Trailing commas are allowed }对应的 SQL 如下:
1 2 3 4 5 6 7 8SELECT COALESCE(SUM(plays), 0) AS plays, MAX(length) AS longest, MIN(length) AS shortest FROM tracks WHERE artist = 'Bob Marley'
总结
参加这次 Apache 大会,HoraeDB 项目算是首次走向国际舞台。与那些已广为人知、炙手可热的项目相比,我们仍然任重而道远。 一个开源项目能够在核心开发团队不断更迭的情况下持续演进,本身就是极其难能可贵的。在 Apache 基金会,我看到了诸多值得学习的典范。
归根结底,软件的生命力在于人,唯有不断壮大社区,源源不断地吸引卓越人才,才能确保社区生生不息、薪火相传。 HoraeDB 目前正处于起步阶段,期许通过社区的持续努力和协作,最终能打造出一个世界一流的云原生时序数据库,在开源的广阔天地中绽放光彩。
欢迎感兴趣的朋友加入我们:https://horaedb.apache.org/community/
2.1.0 版本发布
Apache HoraeDB(孵化中)团队很高兴地宣布,v2.1.0 版本已于 2024-11-18 发布,这个版本解决了 60 多个问题,并且包括两个主要功能:
1. 引入基于本地磁盘的新 WAL 实现
在之前的版本中,有一个基于 RocksDB 的 WAL。虽然它在大多数情况下运行良好,但存在以下问题:
- 从源代码编译可能是一项具有挑战性的任务,尤其是因为 RocksDB 主要是用 C++ 编写的。
- 对于 WAL 而言,RocksDB 可能有些矫枉过正。如果你对 RocksDB 不熟悉,那么对它进行调整可能会非常具有挑战性。
通过这个新的 WAL,就很好的解决了上面两个问题,而且在性能测试结果,新 WAL 的表现略优于之前的实现,给以后的优化打下了结实的基础。
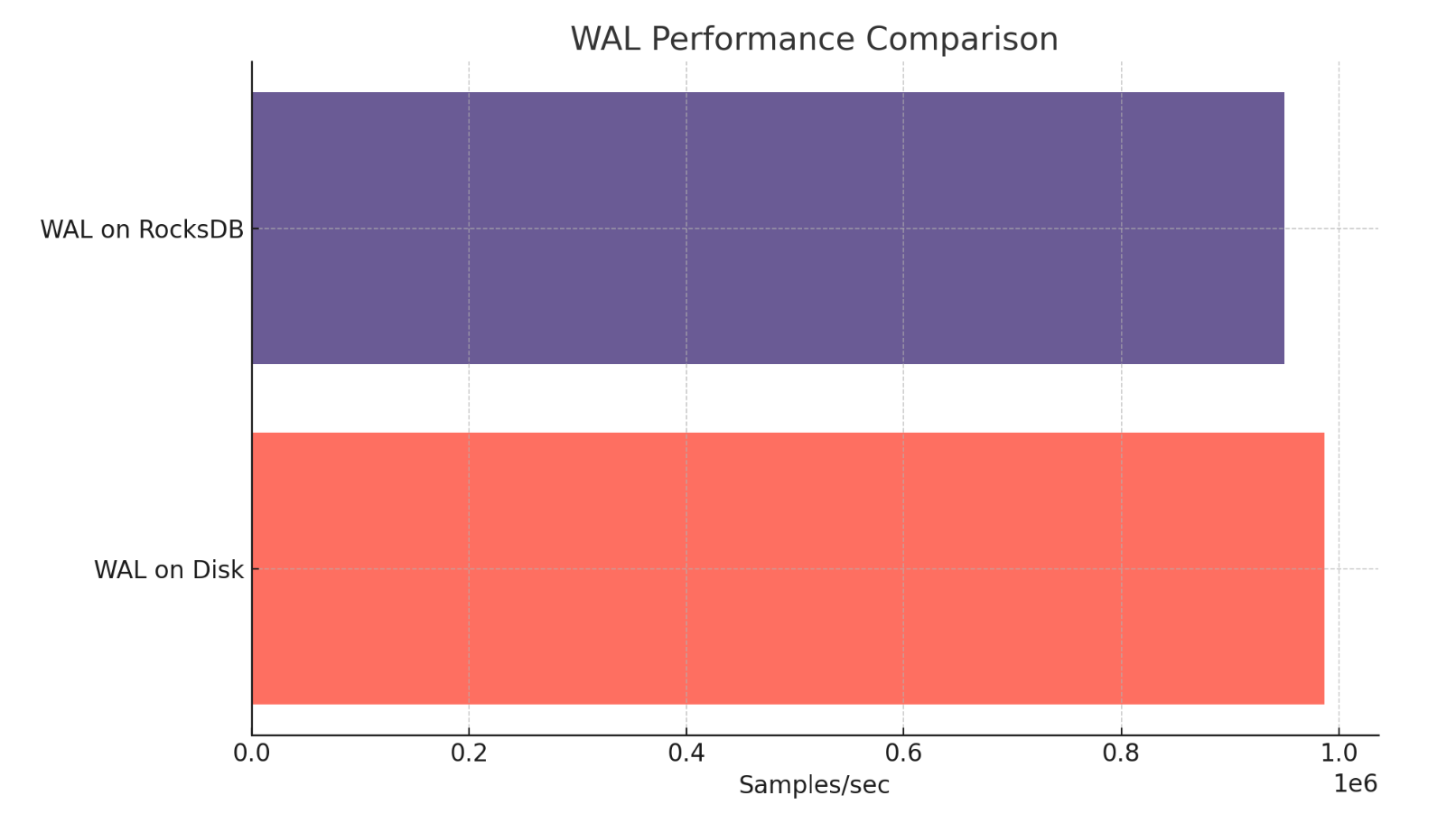
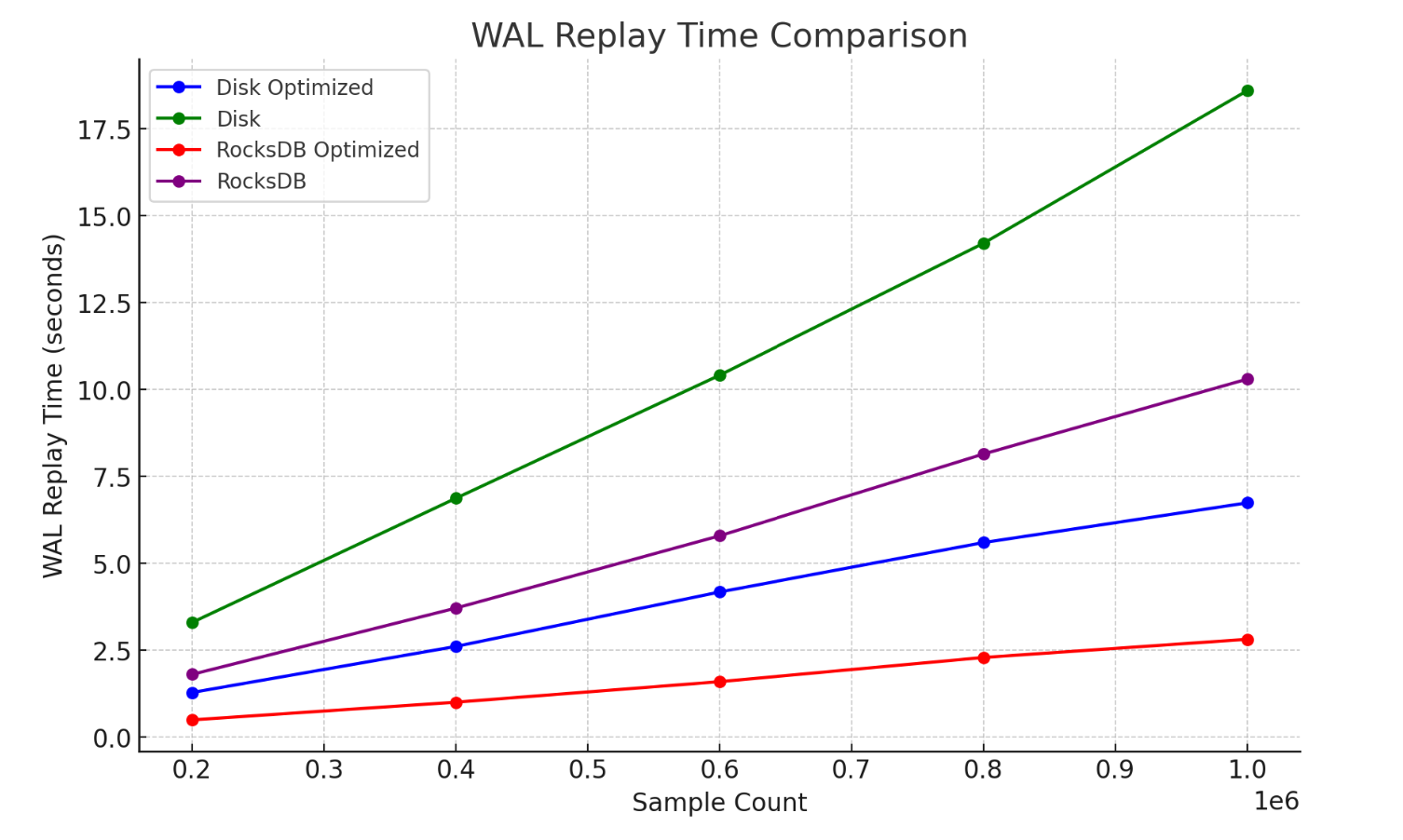
感兴趣的朋友可以参考这里的设计文档了解更多这个特性的细节。
2. 使用 Apache OpenDAL 访问对象存储
Apache OpenDAL 是一个为访问各种数据存储后端提供统一 API 的项目。以下是一些主要优势:
- 统一的 API:OpenDAL 为访问 AWS S3、Azure Blob Storage 和本地文件系统等不同存储后端提供了一致、统一的 API。
- 优化效率:OpenDAL 在构建时就考虑到了性能。它包括确保高效数据访问和操作的优化功能,使其适用于高性能应用程序。
- 全面的文档:该项目提供了详细的文档,使开发人员更容易上手并了解如何有效地使用该库。
在较新版本的 OpenDAL 中,提供了 object_store 的集成,这非常有利于 HoraeDB 的代码迁移,上层使用的 API 几乎没有发生变化,只需要将对象存储抽象为统一的 OpenDAL operator:
| |
此外,由于 Apache OpenDAL 实现的 object_store 是基于最新版本的,相较于 HoraeDB 之前使用的版本,object_store 接口发生了变化,为了保证本次升级范围尽量可控,我们选择对其进行兼容。
对新 API 适配的过程中, put_multipart 接口变化最大,因此主要的适配逻辑也在这里,HoraeDB 的做法是:对底层的 put_multipart 接口进行了封装,保证上层代码无修改,具体细节可参考:
说明:在 parquet 最新版本中,写入路径上对新
put_multipart接口适配程度较高,若用户使用的 parquet 版本 >= 52.0.0,则无需进行适配,若是更老的版本,可参考 HoraeDB 的适配实现。
下载
见下载页面。
总结
其他错误修复和改进请参见此处: https://github.com/apache/horaedb/releases/tag/v2.1.0
我们一如既往地热忱欢迎您加入我们的社区,分享您的真知灼见。
Apache HoraeDB 与你相约北京理工大学
在数字化转型的浪潮中,开源软件人才的培养是信息技术创新发展的重要根基,高校学子作为我国开源生态的源头活水备受重视。10 月 26 日 CCF 开源发展委员会“开源高校行”活动将走进北京理工大学与高校师生交流分享,共同推进开源教育,建立产学研用一体化开源创新人才培养体系。诚邀您的参与!
Apache HoraeDB PPMC 成员 任春韶 将带来 Optimizing Apache HoraeDB for High-Cardinality Metrics at AntGroup 为题的分享,欢迎在场的朋友前来观看、交流 🤝
活动须知
- 时间:2024 年 10 月 26 号 18:30-20:05
- 地点:北京理工大学良乡校区文萃楼 I 405

Apache HoraeDB 与你相约 Community Over Code 北美大会
在数字化浪潮席卷全球的今天,开源软件已成为推动科技创新的核心驱动力。ApacheCon 作为全球最具影响力的开源盛会之一,每年都吸引着来自世界各地的开发者、技术专家和企业代表。
这次 Community Over Code 北美大会将在丹佛君悦大酒店举行为期四天的现场会议,重点讨论搜索、大数据、物联网、社区、地理空间、金融技术和许多其他主题。
Apache HoraeDB PPMC 成员 jiacai2050 将带来 Optimizing Apache HoraeDB for High-Cardinality Metrics at AntGroup 为题的分享,欢迎在场的朋友前来观看、交流 🤝

更多议程内容,可以参考官网的 Sessions Schedule 。
欢迎 Apache HoraeDB 新晋 Committer: 鲍金日
各位开发者们,
今天很高兴宣布,HoraeDB 社区新增了一个 committer:鲍金日,他之前的贡献得到 HoraeDB PPMC 的一致认可,并于 2024-09-10 投票成为 committer,感谢他一直以来的贡献。下面是他的贡献记录:
需要明确一点,成为 committer 并不需要额外做什么,主要是方便开发者后续可以更便利(有仓库写权限)地参与社区贡献。
最后,再次感谢鲍金日一直以来对社区的付出,衷心希望他能继续贡献,共同见证社区的成长。
欢迎更多感兴趣的朋友加入我们的社区,与我们近距离交流。
预告:第一次线上会议
各位开发者们,
欢迎大家参加我们的第一次线上会议!这次会议标志着我们团队在项目开发过程中的一个重要里程碑,也是我们合作共赢的开始。
会议目的
这次会议的主要目的是让大家相互认识,了解项目的总体目标,讨论开发的初步计划,并明确各自的角色和责任。我们希望通过此次会议,能够为接下来的工作奠定坚实的基础,并建立起一个高效、透明的沟通机制。
主要议题
- Apache HoraeDB 项目现状介绍
- 新 Metric Engine 设计方案介绍
参会方式
入会链接:https://meeting.dingtalk.com/j/011mRkbIdqL
可通过浏览器直接入会,无需下载钉钉。
也欢迎感兴趣的朋友可以加入我们的社区(钉钉群、微信公众号等),获取社区最新动态。
会议时间
2024 年 08 月 27 日 周二,21:00-22:00 (GMT+8)