This is the multi-page printable view of this section. Click here to print.
User Guide
- 1: SQL Syntax
- 1.1: Data Model
- 1.1.1: Data Types
- 1.1.2: Special Columns
- 1.2: Identifier
- 1.3: Data Definition Statements
- 1.3.1: ALTER TABLE
- 1.3.2: CREATE TABLE
- 1.3.3: DROP TABLE
- 1.4: Data Manipulation Statements
- 1.5: Utility Statements
- 1.6: Options
- 1.7: Scalar Functions
- 1.8: Aggregate Functions
- 2: Cluster Deployment
- 3: SDK
- 4: Operation and Maintenance
- 4.1: Block List
- 4.2: Cluster Operation
- 4.3: Observability
- 4.4: Table Operation
- 4.5: Table Operation
- 5: Ecosystem
- 5.1: InfluxDB
- 5.2: OpenTSDB
- 5.3: Prometheus
1 - SQL Syntax
1.1 - Data Model
This chapter introduces the data model of HoraeDB.
1.1.1 - Data Types
HoraeDB implements table model, and the supported data types are similar to MySQL. The following table lists the mapping relationship between MySQL and HoraeDB.
Support Data Type(case-insensitive)
| SQL | HoraeDB |
|---|---|
| null | Null |
| timestamp | Timestamp |
| double | Double |
| float | Float |
| string | String |
| Varbinary | Varbinary |
| uint64 | UInt64 |
| uint32 | UInt32 |
| uint16 | UInt16 |
| uint8 | UInt8 |
| int64/bigint | Int64 |
| int32/int | Int32 |
| int16/smallint | Int16 |
| int8/tinyint | Int8 |
| boolean | Boolean |
| date | Date |
| time | Time |
1.1.2 - Special Columns
Tables in HoraeDB have the following constraints:
- Primary key is required
- The primary key must contain a time column, and can only contain one time column
- The primary key must be non-null, so all columns in primary key must be non-null.
Timestamp Column
Tables in HoraeDB must have one timestamp column maps to timestamp in timeseries data, such as timestamp in OpenTSDB/Prometheus.
The timestamp column can be set with timestamp key keyword, like TIMESTAMP KEY(ts).
Tag Column
Tag is use to defined column as tag column, similar to tag in timeseries data, such as tag in OpenTSDB and label in Prometheus.
Primary Key
The primary key is used for data deduplication and sorting. The primary key is composed of some columns and one time column. The primary key can be set in the following some ways:
- use
primary keykeyword - use
tagto auto generate TSID, HoraeDB will use(TSID,timestamp)as primary key - only set Timestamp column, HoraeDB will use
(timestamp)as primary key
Notice: If the primary key and tag are specified at the same time, then the tag column is just an additional information identification and will not affect the logic.
| |
TSID
If primary keyis not set, and tag columns is provided, TSID will auto generated from hash of tag columns.
In essence, this is also a mechanism for automatically generating id.
1.2 - Identifier
Identifier in HoraeDB can be used as table name, column name etc. It cannot be preserved keywords or start with number and punctuation symbols. HoraeDB allows to quote identifiers with back quotes (`). In this case it can be any string like 00_table or select.
1.3 - Data Definition Statements
This chapter introduces the data definition statements.
1.3.1 - ALTER TABLE
ALTER TABLE can change the schema or options of a table.
ALTER TABLE SCHEMA
HoraeDB current supports ADD COLUMN to alter table schema.
| |
It now becomes:
-- DESCRIBE TABLE `t`;
name type is_primary is_nullable is_tag
t timestamp true false false
tsid uint64 true false false
a int false true false
b string false true false
ALTER TABLE OPTIONS
HoraeDB current supports MODIFY SETTING to alter table schema.
| |
The SQL above tries to modify the write_buffer_size of the table, and the table’s option becomes:
| |
Besides, the ttl can be altered from 7 days to 10 days by such SQL:
| |
1.3.2 - CREATE TABLE
Basic syntax
Basic syntax:
| |
Column definition syntax:
| |
Partition options syntax:
| |
Table options syntax are key-value pairs. Value should be quoted with quotation marks ('). E.g.:
| |
IF NOT EXISTS
Add IF NOT EXISTS to tell HoraeDB to ignore errors if the table name already exists.
Define Column
A column’s definition should at least contains the name and type parts. All supported types are listed here.
Column is default be nullable. i.e. NULL keyword is implied. Adding NOT NULL constrains to make it required.
| |
A column can be marked as special column with related keyword.
For string tag column, we recommend to define it as dictionary to reduce memory consumption:
| |
Engine
Specifies which engine this table belongs to. HoraeDB current support Analytic engine type. This attribute is immutable.
Partition Options
Note: This feature is only supported in distributed version.
| |
Example below creates a table with 8 partitions, and partitioned by name:
| |
1.3.3 - DROP TABLE
Basic syntax
Basic syntax:
| |
Drop Table removes a specific table. This statement should be used with caution, because it removes both the table definition and table data, and this removal is not recoverable.
1.4 - Data Manipulation Statements
This chapter introduces the data manipulation statements.
1.4.1 - INSERT
Basic syntax
Basic syntax:
| |
INSERT inserts new rows into a HoraeDB table. Here is an example:
| |
1.4.2 - SELECT
Basic syntax
Basic syntax (parts between [] are optional):
| |
Select syntax in HoraeDB is similar to mysql, here is an example:
| |
1.5 - Utility Statements
There are serval utilities SQL in HoraeDB that can help in table manipulation or query inspection.
SHOW CREATE TABLE
| |
SHOW CREATE TABLE returns a CREATE TABLE DDL that will create a same table with the given one. Including columns, table engine and options. The schema and options shows in CREATE TABLE will based on the current version of the table. An example:
| |
DESCRIBE
| |
DESCRIBE will show a detailed schema of one table. The attributes include column name and type, whether it is tag and primary key (todo: ref) and whether it’s nullable. The auto created column tsid will also be included (todo: ref).
Example:
| |
The result is:
name type is_primary is_nullable is_tag
t timestamp true false false
tsid uint64 true false false
a int false true false
b string false true false
EXPLAIN
| |
EXPLAIN shows how a query will be executed. Add it to the beginning of a query like
| |
will give
logical_plan
Projection: #MAX(07_optimizer_t.value) AS c1, #AVG(07_optimizer_t.value) AS c2
Aggregate: groupBy=[[#07_optimizer_t.name]], aggr=[[MAX(#07_optimizer_t.value), AVG(#07_optimizer_t.value)]]
TableScan: 07_optimizer_t projection=Some([name, value])
physical_plan
ProjectionExec: expr=[MAX(07_optimizer_t.value)@1 as c1, AVG(07_optimizer_t.value)@2 as c2]
AggregateExec: mode=FinalPartitioned, gby=[name@0 as name], aggr=[MAX(07_optimizer_t.value), AVG(07_optimizer_t.value)]
CoalesceBatchesExec: target_batch_size=4096
RepartitionExec: partitioning=Hash([Column { name: \"name\", index: 0 }], 6)
AggregateExec: mode=Partial, gby=[name@0 as name], aggr=[MAX(07_optimizer_t.value), AVG(07_optimizer_t.value)]
ScanTable: table=07_optimizer_t, parallelism=8, order=None
1.6 - Options
Options below can be used when create table for analytic engine
enable_ttl,bool. When enable TTL on a table, rows older thanttlwill be deleted and can’t be querid, defaulttruettl,duration, lifetime of a row, only used whenenable_ttlistrue. default7d.storage_format,string. The underlying column’s format. Availiable values:columnar, defaulthybrid, Note: This feature is still in development, and it may change in the future.
The meaning of those two values are in Storage format section.
Storage Format
There are mainly two formats supported in analytic engine. One is columnar, which is the traditional columnar format, with one table column in one physical column:
| |
The other one is hybrid, an experimental format used to simulate row-oriented storage in columnar storage to accelerate classic time-series query.
In classic time-series user cases like IoT or DevOps, queries will typically first group their result by series id(or device id), then by timestamp. In order to achieve good performance in those scenarios, the data physical layout should match this style, so the hybrid format is proposed like this:
| |
- Within one file, rows belonging to the same primary key(eg: series/device id) are collapsed into one row
- The columns besides primary key are divided into two categories:
collapsible, those columns will be collapsed into a list. Used to encodefieldsin time-series table- Note: only fixed-length type is supported now
non-collapsible, those columns should only contain one distinct value. Used to encodetagsin time-series table- Note: only string type is supported now
- Two more columns are added,
minTimeandmaxTime. Those are used to cut unnecessary rows out in query.- Note: Not implemented yet.
Example
| |
This will create a table with hybrid format, users can inspect data format with parquet-tools. The table above should have following parquet schema:
message arrow_schema {
optional group ts (LIST) {
repeated group list {
optional int64 item (TIMESTAMP(MILLIS,false));
}
}
required int64 tsid (INTEGER(64,false));
optional binary tag1 (STRING);
optional binary tag2 (STRING);
optional group value1 (LIST) {
repeated group list {
optional double item;
}
}
optional group value2 (LIST) {
repeated group list {
optional int32 item;
}
}
}
1.7 - Scalar Functions
HoraeDB SQL is implemented with DataFusion, Here is the list of scalar functions. See more detail, Refer to Datafusion
Math Functions
| Function | Description |
|---|---|
| abs(x) | absolute value |
| acos(x) | inverse cosine |
| asin(x) | inverse sine |
| atan(x) | inverse tangent |
| atan2(y, x) | inverse tangent of y / x |
| ceil(x) | nearest integer greater than or equal to argument |
| cos(x) | cosine |
| exp(x) | exponential |
| floor(x) | nearest integer less than or equal to argument |
| ln(x) | natural logarithm |
| log10(x) | base 10 logarithm |
| log2(x) | base 2 logarithm |
| power(base, exponent) | base raised to the power of exponent |
| round(x) | round to nearest integer |
| signum(x) | sign of the argument (-1, 0, +1) |
| sin(x) | sine |
| sqrt(x) | square root |
| tan(x) | tangent |
| trunc(x) | truncate toward zero |
Conditional Functions
| Function | Description |
|---|---|
| coalesce | Returns the first of its arguments that is not null. Null is returned only if all arguments are null. It is often used to substitute a default value for null values when data is retrieved for display. |
| nullif | Returns a null value if value1 equals value2; otherwise it returns value1. This can be used to perform the inverse operation of the coalesce expression. |
String Functions
| Function | Description |
|---|---|
| ascii | Returns the numeric code of the first character of the argument. In UTF8 encoding, returns the Unicode code point of the character. In other multibyte encodings, the argument must be an ASCII character. |
| bit_length | Returns the number of bits in a character string expression. |
| btrim | Removes the longest string containing any of the specified characters from the start and end of string. |
| char_length | Equivalent to length. |
| character_length | Equivalent to length. |
| concat | Concatenates two or more strings into one string. |
| concat_ws | Combines two values with a given separator. |
| chr | Returns the character based on the number code. |
| initcap | Capitalizes the first letter of each word in a string. |
| left | Returns the specified leftmost characters of a string. |
| length | Returns the number of characters in a string. |
| lower | Converts all characters in a string to their lower case equivalent. |
| lpad | Left-pads a string to a given length with a specific set of characters. |
| ltrim | Removes the longest string containing any of the characters in characters from the start of string. |
| md5 | Calculates the MD5 hash of a given string. |
| octet_length | Equivalent to length. |
| repeat | Returns a string consisting of the input string repeated a specified number of times. |
| replace | Replaces all occurrences in a string of a substring with a new substring. |
| reverse | Reverses a string. |
| right | Returns the specified rightmost characters of a string. |
| rpad | Right-pads a string to a given length with a specific set of characters. |
| rtrim | Removes the longest string containing any of the characters in characters from the end of string. |
| digest | Calculates the hash of a given string. |
| split_part | Splits a string on a specified delimiter and returns the specified field from the resulting array. |
| starts_with | Checks whether a string starts with a particular substring. |
| strpos | Searches a string for a specific substring and returns its position. |
| substr | Extracts a substring of a string. |
| translate | Translates one set of characters into another. |
| trim | Removes the longest string containing any of the characters in characters from either the start or end of string. |
| upper | Converts all characters in a string to their upper case equivalent. |
Regular Expression Functions
| Function | Description |
|---|---|
| regexp_match | Determines whether a string matches a regular expression pattern. |
| regexp_replace | Replaces all occurrences in a string of a substring that matches a regular expression pattern with a new substring. |
Temporal Functions
| Function | Description |
|---|---|
| to_timestamp | Converts a string to type Timestamp(Nanoseconds, None). |
| to_timestamp_millis | Converts a string to type Timestamp(Milliseconds, None). |
| to_timestamp_micros | Converts a string to type Timestamp(Microseconds, None). |
| to_timestamp_seconds | Converts a string to type Timestamp(Seconds, None). |
| extract | Retrieves subfields such as year or hour from date/time values. |
| date_part | Retrieves subfield from date/time values. |
| date_trunc | Truncates date/time values to specified precision. |
| date_bin | Bin date/time values to specified precision. |
| from_unixtime | Converts Unix epoch to type Timestamp(Nanoseconds, None). |
| now | Returns current time as Timestamp(Nanoseconds, UTC). |
Other Functions
| Function | Description |
|---|---|
| array | Create an array. |
| arrow_typeof | Returns underlying type. |
| in_list | Check if value in list. |
| random | Generate random value. |
| sha224 | sha224 |
| sha256 | sha256 |
| sha384 | sha384 |
| sha512 | sha512 |
| to_hex | Convert to hex. |
1.8 - Aggregate Functions
HoraeDB SQL is implemented with DataFusion, Here is the list of aggregate functions. See more detail, Refer to Datafusion
General
| Function | Description |
|---|---|
| min | Returns the minimum value in a numerical column |
| max | Returns the maximum value in a numerical column |
| count | Returns the number of rows |
| avg | Returns the average of a numerical column |
| sum | Sums a numerical column |
| array_agg | Puts values into an array |
Statistical
| Function | Description |
|---|---|
| var / var_samp | Returns the variance of a given column |
| var_pop | Returns the population variance of a given column |
| stddev / stddev_samp | Returns the standard deviation of a given column |
| stddev_pop | Returns the population standard deviation of a given column |
| covar / covar_samp | Returns the covariance of a given column |
| covar_pop | Returns the population covariance of a given column |
| corr | Returns the correlation coefficient of a given column |
Approximate
| Function | Description |
|---|---|
| approx_distinct | Returns the approximate number (HyperLogLog) of distinct input values |
| approx_median | Returns the approximate median of input values. It is an alias of approx_percentile_cont(x, 0.5). |
| approx_percentile_cont | Returns the approximate percentile (TDigest) of input values, where p is a float64 between 0 and 1 (inclusive). It supports raw data as input and build Tdigest sketches during query time, and is approximately equal to approx_percentile_cont_with_weight(x, 1, p). |
| approx_percentile_cont_with_weight | Returns the approximate percentile (TDigest) of input values with weight, where w is weight column expression and p is a float64 between 0 and 1 (inclusive). It supports raw data as input or pre-aggregated TDigest sketches, then builds or merges Tdigest sketches during query time. TDigest sketches are a list of centroid (x, w), where x stands for mean and w stands for weight. |
2 - Cluster Deployment
In the Getting Started section, we have introduced the deployment of single HoraeDB instance.
Besides, as a distributed timeseries database, multiple HoraeDB instances can be deployed as a cluster to serve with high availability and scalability.
Currently, work about the integration with kubernetes is still in process, so HoraeDB cluster can only be deployed manually. And there are two modes of cluster deployment:
2.1 - NoMeta
Note: This feature is for testing use only, not recommended for production use, related features may change in the future.
This guide shows how to deploy a HoraeDB cluster without HoraeMeta, but with static, rule-based routing.
The crucial point here is that HoraeDB server provides configurable routing function on table name so what we need is just a valid config containing routing rules which will be shipped to every HoraeDB instance in the cluster.
Target
First, let’s assume that our target is to deploy a cluster consisting of two HoraeDB instances on the same machine. And a large cluster of more HoraeDB instances can be deployed according to the two-instance example.
Prepare Config
Basic
Suppose the basic config of HoraeDB is:
| |
In order to deploy two HoraeDB instances on the same machine, the config should choose different ports to serve and data directories to store data.
Say the HoraeDB_0’s config is:
| |
Then the HoraeDB_1’s config is:
| |
Schema&Shard Declaration
Then we should define the common part – schema&shard declaration and routing rules.
Here is the config for schema&shard declaration:
| |
In the config above, two schemas are declared:
public_0has two shards served byHoraeDB_0.public_1has two shards served by bothHoraeDB_0andHoraeDB_1.
Routing Rules
Provided with schema&shard declaration, routing rules can be defined and here is an example of prefix rule:
| |
This rule means that all the table with prod_ prefix belonging to public_0 should be routed to shard_0 of public_0, that is to say, HoraeDB_0. As for the other tables whose names are not prefixed by prod_ will be routed by hash to both shard_0 and shard_1 of public_0.
Besides prefix rule, we can also define a hash rule:
| |
This rule tells HoraeDB to route public_1’s tables to both shard_0 and shard_1 of public_1, that is to say, HoraeDB0 and HoraeDB_1. And actually this is default routing behavior if no such rule provided for schema public_1.
For now, we can provide the full example config for HoraeDB_0 and HoraeDB_1:
| |
| |
Let’s name the two different config files as config_0.toml and config_1.toml but you should know in the real environment the different HoraeDB instances can be deployed across different machines, that is to say, there is no need to choose different ports and data directories for different HoraeDB instances so that all the HoraeDB instances can share one exactly same config file.
Start HoraeDBs
After the configs are prepared, what we should to do is to start HoraeDB container with the specific config.
Just run the commands below:
| |
After the two containers are created and starting running, read and write requests can be served by the two-instances HoraeDB cluster.
2.2 - WithMeta
This guide shows how to deploy a HoraeDB cluster with HoraeMeta. And with the HoraeMeta, the whole HoraeDB cluster will feature: high availability, load balancing and horizontal scalability if the underlying storage used by HoraeDB is separated service.
Deploy HoraeMeta
Introduce
HoraeMeta is one of the core services of HoraeDB distributed mode, it is used to manage and schedule the HoraeDB cluster. By the way, the high availability of HoraeMeta is ensured by embedding ETCD. Also, the ETCD service is provided for HoraeDB servers to manage the distributed shard locks.
Build
- Golang version >= 1.19.
- run
make buildin root path of HoraeMeta.
Deploy
Config
At present, HoraeMeta supports specifying service startup configuration in two ways: configuration file and environment variable. We provide an example of configuration file startup. For details, please refer to config. The configuration priority of environment variables is higher than that of configuration files. When they exist at the same time, the environment variables shall prevail.
Dynamic or Static
Even with the HoraeMeta, the HoraeDB cluster can be deployed with a static or a dynamic topology. With a static topology, the table distribution is static after the cluster is initialized while with the dynamic topology, the tables can migrate between different HoraeDB nodes to achieve load balance or failover. However, the dynamic topology can be enabled only if the storage used by the HoraeDB node is remote, otherwise the data may be corrupted when tables are transferred to a different HoraeDB node when the data of HoraeDB is persisted locally.
Currently, the dynamic scheduling over the cluster topology is disabled by default in HoraeMeta, and in this guide, we won’t enable it because local storage is adopted here. If you want to enable the dynamic scheduling, the TOPOLOGY_TYPE can be set as dynamic (static by default), and after that, load balancing and failover will work. However, don’t enable it if what the underlying storage is local disk.
With the static topology, the params DEFAULT_CLUSTER_NODE_COUNT, which denotes the number of the HoraeDB nodes in the deployed cluster and should be set to the real number of machines for HoraeDB server, matters a lot because after cluster initialization the HoraeDB nodes can’t be changed any more.
Start HoraeMeta Instances
HoraeMeta is based on etcd to achieve high availability. In product environment, we usually deploy multiple nodes, but in local environment and testing, we can directly deploy a single node to simplify the entire deployment process.
- Standalone
| |
- Cluster
| |
And if the storage used by the HoraeDB is remote and you want to enable the dynamic schedule features of the HoraeDB cluster, the -e TOPOLOGY_TYPE=dynamic can be added to the docker run command.
Deploy HoraeDB
In the NoMeta mode, HoraeDB only requires the local disk as the underlying storage because the topology of the HoraeDB cluster is static. However, with HoraeMeta, the cluster topology can be dynamic, that is to say, HoraeDB can be configured to use a non-local storage service for the features of a distributed system: HA, load balancing, scalability and so on. And HoraeDB can be still configured to use a local storage with HoraeMeta, which certainly leads to a static cluster topology.
The relevant storage configurations include two parts:
- Object Storage
- WAL Storage
Note: If you are deploying HoraeDB over multiple nodes in a production environment, please set the environment variable for the server address as follows:
| |
This address is used for communication between HoraeMeta and HoraeDB, please ensure it is valid.
Object Storage
Local Storage
Similarly, we can configure HoraeDB to use a local disk as the underlying storage:
| |
OSS
Aliyun OSS can be also used as the underlying storage for HoraeDB, with which the data is replicated for disaster recovery. Here is a example config, and you have to replace the templates with the real OSS parameters:
| |
S3
Amazon S3 can be also used as the underlying storage for HoraeDB. Here is a example config, and you have to replace the templates with the real S3 parameters:
| |
WAL Storage
RocksDB
The WAL based on RocksDB is also a kind of local storage for HoraeDB, which is easy for a quick start:
| |
OceanBase
If you have deployed a OceanBase cluster, HoraeDB can use it as the WAL storage for data disaster recovery. Here is a example config for such WAL, and you have to replace the templates with real OceanBase parameters:
| |
Kafka
If you have deployed a Kafka cluster, HoraeDB can also use it as the WAL storage. Here is example config for it, and you have to replace the templates with real parameters of the Kafka cluster:
| |
Meta Client Config
Besides the storage configurations, HoraeDB must be configured to start in WithMeta mode and connect to the deployed HoraeMeta:
| |
Compaction Offload
Compaction offload is also supported. To enable compaction offload, the corresponding compaction mode with node picker and endpoint should be configured.
node_picker: There are two types of node picker –LocalandRemote(WIP).- When the
Localis setted, the local compaction task would be offloaded to the specific remote compaction server, which decided byendpoint.
- When the
endpoint: The endpoint, in the formaddr:port, indicating the grpc port of the remote compaction server.
Here is an example for it:
| |
A Compaction Server, responsible for executing the compaction task, is also needed. Currently horaedb-server will act as this role, in the future we can move it to an independent service.
Complete Config of HoraeDB
With all the parts of the configurations mentioned above, a runnable complete config for HoraeDB can be made. In order to make the HoraeDB cluster runnable, we can decide to adopt RocksDB-based WAL and local-disk-based Object Storage without compaction offload:
| |
Let’s name this config file as config.toml. And the example configs, in which the templates must be replaced with real parameters before use, for remote storages are also provided:
Run HoraeDB cluster with HoraeMeta
Firstly, let’s start the HoraeMeta:
| |
With the started HoraeMeta cluster, let’s start the HoraeDB instance: TODO: complete it later
3 - SDK
3.1 - Go
Installation
go get github.com/apache/incubator-horaedb-client-go
You can get latest version here.
How To Use
Init HoraeDB Client
| |
| option name | description |
|---|---|
| defaultDatabase | using database, database can be overwritten by ReqContext in single Write or SQLRequest |
| RPCMaxRecvMsgSize | configration for grpc MaxCallRecvMsgSize, default 1024 _ 1024 _ 1024 |
| RouteMaxCacheSize | If the maximum number of router cache size, router client whill evict oldest if exceeded, default is 10000 |
Notice:
- HoraeDB currently only supports the default database
publicnow, multiple databases will be supported in the future
Manage Table
HoraeDB uses SQL to manage tables, such as creating tables, deleting tables, or adding columns, etc., which is not much different from when you use SQL to manage other databases.
For ease of use, when using gRPC’s write interface for writing, if a table does not exist, HoraeDB will automatically create a table based on the first write.
Of course, you can also use create table statement to manage the table more finely (such as adding indexes).
Example for creating table
| |
Example for droping table
| |
How To Build Write Data
| |
Write Example
| |
Query Example
| |
Example
You can find the complete example here.
3.2 - Java
Introduction
HoraeDB Client is a high-performance Java client for HoraeDB.
Requirements
- Java 8 or later is required for compilation
Dependency
| |
You can get latest version here.
Init HoraeDB Client
| |
The initialization requires at least three parameters:
Endpoint: 127.0.0.1Port: 8831RouteMode: DIRECT/PROXY
Here is the explanation of RouteMode. There are two kinds of RouteMode,The Direct mode should be adopted to avoid forwarding overhead if all the servers are accessible to the client.
However, the Proxy mode is the only choice if the access to the servers from the client must go through a gateway.
For more configuration options, see configuration
Notice: HoraeDB currently only supports the default database public now, multiple databases will be supported in the future;
Create Table Example
For ease of use, when using gRPC’s write interface for writing, if a table does not exist, HoraeDB will automatically create a table based on the first write.
Of course, you can also use create table statement to manage the table more finely (such as adding indexes).
The following table creation statement(using the SQL API included in SDK )shows all field types supported by HoraeDB:
| |
Drop Table Example
Here is an example of dropping table:
| |
Write Data Example
Firstly, you can use PointBuilder to build HoraeDB points:
| |
Then, you can use write interface to write data:
| |
See write
Query Data Example
| |
See read
Stream Write/Read Example
HoraeDB support streaming writing and reading,suitable for large-scale data reading and writing。
| |
See streaming
3.3 - Python


Introduction
horaedb-client is the python client for HoraeDB.
Thanks to PyO3, the python client is actually a wrapper on the rust client.
The guide will give a basic introduction to the python client by example.
Requirements
- Python >= 3.7
Installation
| |
You can get latest version here.
Init HoraeDB Client
The client initialization comes first, here is a code snippet:
| |
Firstly, it’s worth noting that the imported packages are used across all the code snippets in this guide, and they will not be repeated in the following.
The initialization requires at least two parameters:
Endpoint: the server endpoint consisting of ip address and serving port, e.g.127.0.0.1:8831;Mode: The mode of the communication between client and server, and there are two kinds ofMode:DirectandProxy.
Endpoint is simple, while Mode deserves more explanation. The Direct mode should be adopted to avoid forwarding overhead if all the servers are accessible to the client. However, the Proxy mode is the only choice if the access to the servers from the client must go through a gateway.
The default_database can be set and will be used if following rpc calling without setting the database in the RpcContext.
By configuring the RpcConfig, resource and performance of the client can be manipulated, and all of the configurations can be referred at here.
Create Table
For ease of use, when using gRPC’s write interface for writing, if a table does not exist, HoraeDB will automatically create a table based on the first write.
Of course, you can also use create table statement to manage the table more finely (such as adding indexes).
Here is a example for creating table by the initialized client:
| |
RpcContext can be used to overwrite the default database and timeout defined in the initialization of the client.
Write Data
PointBuilder can be used to construct a point, which is actually a row in data set. The write request consists of multiple points.
The example is simple:
| |
Query Data
By sql_query interface, it is easy to retrieve the data from the server:
req = SqlQueryRequest(['demo'], 'select * from demo')
event_loop = asyncio.get_event_loop()
resp = event_loop.run_until_complete(async_query(client, ctx, req))
As the example shows, two parameters are needed to construct the SqlQueryRequest:
- The tables involved by this sql query;
- The query sql.
Currently, the first parameter is necessary for performance on routing.
With retrieved data, we can process it row by row and column by column:
| |
Drop Table
Finally, we can drop the table by the sql api, which is similar to the table creation:
| |
3.4 - Rust


Install
| |
You can get latest version here.
Init Client
At first, we need to init the client.
- New builder for the client, and you must set
endpointandmode:endpointis a string which is usually like “ip/domain_name:port”.modeis used to define the way to access horaedb server, detail about mode.
| |
- New and set
rpc_config, it can be defined on demand or just use the default value, detail about rpc config:
| |
- Set
default_database, it will be used if following rpc calling without setting the database in theRpcContext(will be introduced in later):
| |
- Finally, we build client from builder:
| |
Manage Table
For ease of use, when using gRPC’s write interface for writing, if a table does not exist, HoraeDB will automatically create a table based on the first write.
Of course, you can also use create table statement to manage the table more finely (such as adding indexes).
You can use the sql query interface to create or drop table, related setting will be introduced in sql query section.
- Create table:
| |
- Drop table:
| |
Write
We support to write with the time series data model like InfluxDB.
- Build the
pointfirst byPointBuilder, the related data structure oftag valueandfield valuein it is defined asValue, detail about Value:
| |
- Add the
pointtowrite request:
| |
New
rpc_ctx, and it can also be defined on demand or just use the default value, detail about rpc ctx:Finally, write to server by client.
| |
Sql Query
We support to query data with sql.
- Define related tables and sql in
sql query request:
| |
- Query by client:
| |
Example
You can find the complete example in the project.
4 - Operation and Maintenance
This guide introduces the operation and maintenance of HoraeDB, including cluster installation, database&table operations, fault tolerance, disaster recovery, data import and export, etc.
4.1 - Block List
Add block list
If you want to reject query for a table, you can add table name to ‘read_block_list’.
Example
| |
Response
| |
Set block list
You can use set operation to clear exist tables and set new tables to ‘read_block_list’ like following example.
Example
| |
Response
| |
Remove block list
You can remove tables from ‘read_block_list’ like following example.
Example
| |
Response
| |
4.2 - Cluster Operation
The Operations for HoraeDB cluster mode, it can only be used when HoraeMeta is deployed.
Operation Interface
You need to replace 127.0.0.1 with the actual project path.
- Query table When tableNames is not empty, use tableNames for query. When tableNames is empty, ids are used for query. When querying with ids, schemaName is useless.
curl --location 'http://127.0.0.1:8080/api/v1/table/query' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"schemaName":"public",
"names":["demo1", "__demo1_0"],
}'
curl --location 'http://127.0.0.1:8080/api/v1/table/query' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"ids":[0, 1]
}'
- Query the route of table
curl --location --request POST 'http://127.0.0.1:8080/api/v1/route' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"schemaName":"public",
"table":["demo"]
}'
- Query the mapping of shard and node
curl --location --request POST 'http://127.0.0.1:8080/api/v1/getNodeShards' \
--header 'Content-Type: application/json' \
-d '{
"ClusterName":"defaultCluster"
}'
- Query the mapping of table and shard If ShardIDs in the request is empty, query with all shardIDs in the cluster.
curl --location --request POST 'http://127.0.0.1:8080/api/v1/getShardTables' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"shardIDs": [1,2]
}'
- Drop table
curl --location --request POST 'http://127.0.0.1:8080/api/v1/dropTable' \
--header 'Content-Type: application/json' \
-d '{
"clusterName": "defaultCluster",
"schemaName": "public",
"table": "demo"
}'
- Transfer leader shard
curl --location --request POST 'http://127.0.0.1:8080/api/v1/transferLeader' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"shardID": 1,
"oldLeaderNodeName": "127.0.0.1:8831",
"newLeaderNodeName": "127.0.0.1:18831"
}'
- Split shard
curl --location --request POST 'http://127.0.0.1:8080/api/v1/split' \
--header 'Content-Type: application/json' \
-d '{
"clusterName" : "defaultCluster",
"schemaName" :"public",
"nodeName" :"127.0.0.1:8831",
"shardID" : 0,
"splitTables":["demo"]
}'
- Create cluster
curl --location 'http://127.0.0.1:8080/api/v1/clusters' \
--header 'Content-Type: application/json' \
--data '{
"name":"testCluster",
"nodeCount":3,
"shardTotal":9,
"topologyType":"static"
}'
- Update cluster
curl --location --request PUT 'http://127.0.0.1:8080/api/v1/clusters/{NewClusterName}' \
--header 'Content-Type: application/json' \
--data '{
"nodeCount":28,
"shardTotal":128,
"topologyType":"dynamic"
}'
- List clusters
curl --location 'http://127.0.0.1:8080/api/v1/clusters'
- Update
enableSchedule
curl --location --request PUT 'http://127.0.0.1:8080/api/v1/clusters/{ClusterName}/enableSchedule' \
--header 'Content-Type: application/json' \
--data '{
"enable":true
}'
- Query
enableSchedule
curl --location 'http://127.0.0.1:8080/api/v1/clusters/{ClusterName}/enableSchedule'
- Update flow limiter
curl --location --request PUT 'http://127.0.0.1:8080/api/v1/flowLimiter' \
--header 'Content-Type: application/json' \
--data '{
"limit":1000,
"burst":10000,
"enable":true
}'
- Query information of flow limiter
curl --location 'http://127.0.0.1:8080/api/v1/flowLimiter'
- List nodes of HoraeMeta cluster
curl --location 'http://127.0.0.1:8080/api/v1/etcd/member'
- Move leader of HoraeMeta cluster
curl --location 'http://127.0.0.1:8080/api/v1/etcd/moveLeader' \
--header 'Content-Type: application/json' \
--data '{
"memberName":"meta1"
}'
- Add node of HoraeMeta cluster
curl --location --request PUT 'http://127.0.0.1:8080/api/v1/etcd/member' \
--header 'Content-Type: application/json' \
--data '{
"memberAddrs":["http://127.0.0.1:42380"]
}'
- Replace node of HoraeMeta cluster
curl --location 'http://127.0.0.1:8080/api/v1/etcd/member' \
--header 'Content-Type: application/json' \
--data '{
"oldMemberName":"meta0",
"newMemberAddr":["http://127.0.0.1:42380"]
}'
4.3 - Observability
HoraeDB is observable with Prometheus and Grafana.
Prometheus
Prometheus is a systems and service monitoring system.
Configuration
Save the following configuration into the prometheus.yml file. For example, in the tmp directory, /tmp/prometheus.yml.
Two HoraeDB http service are started on localhost:5440 and localhost:5441.
| |
See details about configuration here.
Run
You can use docker to start Prometheus. The docker image information is here.
docker run \
-d --name=prometheus \
-p 9090:9090 \
-v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus:v2.41.0
For more detailed installation methods, refer to here.
Grafana
Grafana is an open and composable observability and data visualization platform.
Run
You can use docker to start grafana. The docker image information is here.
docker run -d --name=grafana -p 3000:3000 grafana/grafana:9.3.6
Default admin user credentials are admin/admin.
Grafana is available on http://127.0.0.1:3000.
For more detailed installation methods, refer to here.
Configure data source
- Hover the cursor over the Configuration (gear) icon.
- Select Data Sources.
- Select the Prometheus data source.
Note: The url of Prometheus is http://your_ip:9090.
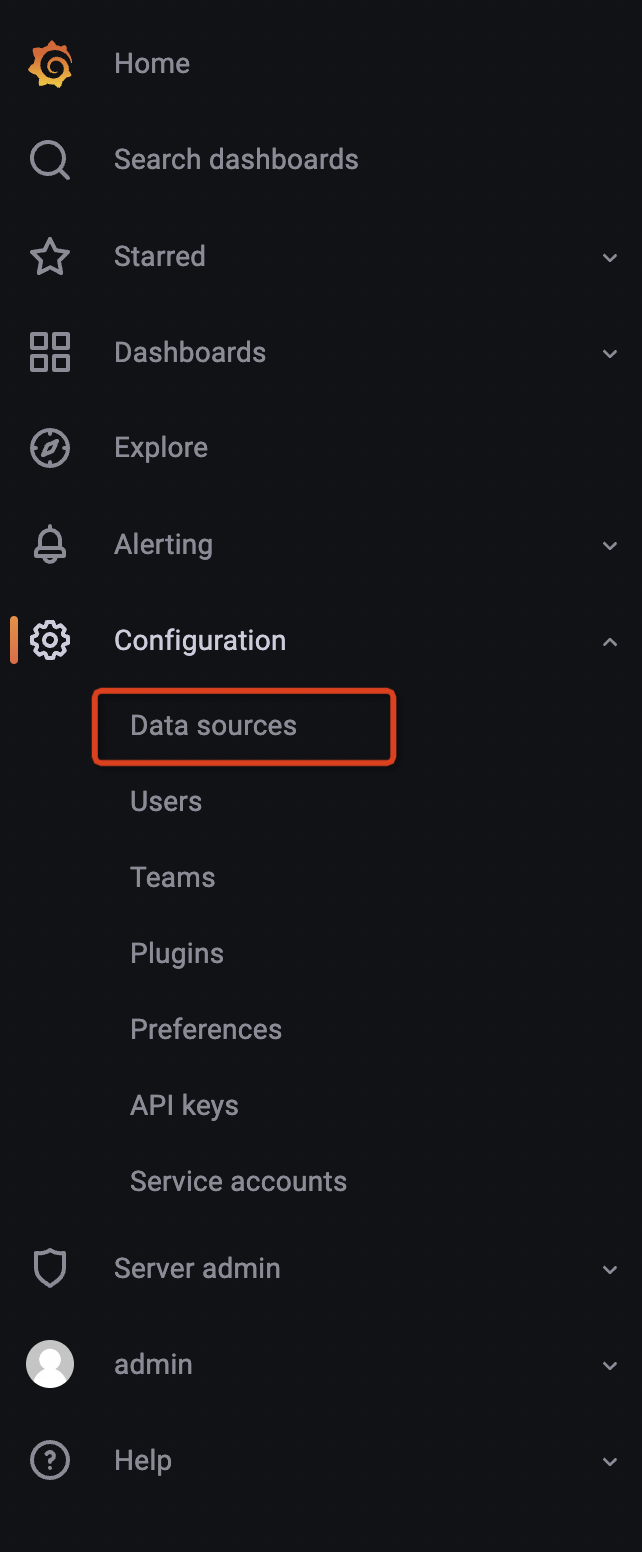
See more details here.
Import grafana dashboard
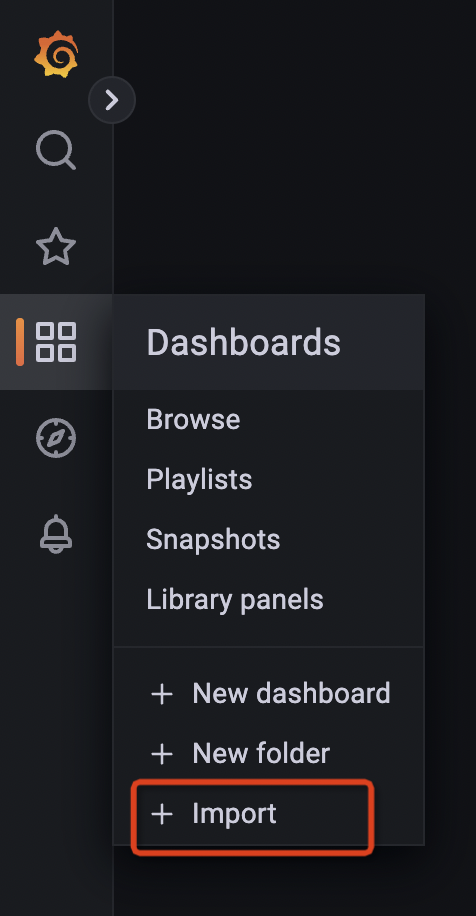
HoraeDB Metrics
After importing the dashboard, you will see the following page:
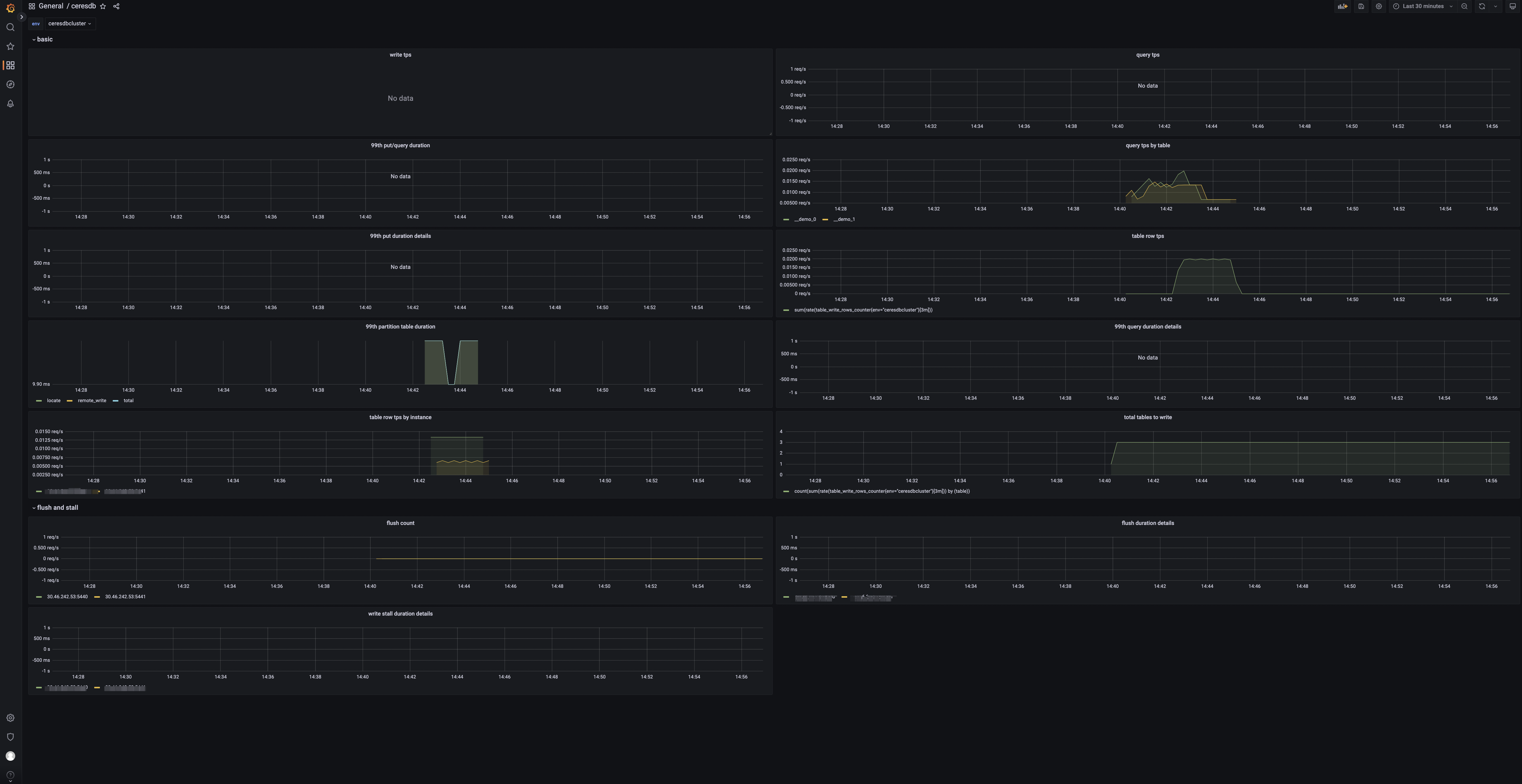
Panels
- tps: Number of cluster write requests.
- qps: Number of cluster query requests.
- 99th query/write duration: 99th quantile of write and query duration.
- table query: Query group by table.
- 99th write duration details by instance: 99th quantile of write duration group by instance.
- 99th query duration details by instance: 99th quantile of query duration group by instance.
- 99th write partition table duration: 99th quantile of write duration of partition table.
- table rows: The rows of data written.
- table rows by instance: The written rows by instance.
- total tables to write: Number of tables with data written.
- flush count: Number of HoraeDB flush.
- 99th flush duration details by instance: 99th quantile of flush duration group by instance.
- 99th write stall duration details by instance: 99th quantile of write stall duration group by instance.
4.4 - Table Operation
Query Table Information
Like Mysql’s information_schema.tables, HoraeDB provides system.public.tables to save tables information.
Columns:
- timestamp([TimeStamp])
- catalog([String])
- schema([String])
- table_name([String])
- table_id([Uint64])
- engine([String])
Example
Query table information via table_name like this:
| |
Response
| |
4.5 - Table Operation
HoraeDB supports standard SQL protocols and allows you to create tables and read/write data via http requests. More SQL
Create Table
Example
| |
Write Data
Example
| |
Read Data
Example
| |
Query Table Info
Example
| |
Drop Table
Example
| |
Route Table
Example
| |
5 - Ecosystem
HoraeDB has an open ecosystem that encourages collaboration and innovation, allowing developers to use what suits them best.
5.1 - InfluxDB
InfluxDB is a time series database designed to handle high write and query loads. It is an integral component of the TICK stack. InfluxDB is meant to be used as a backing store for any use case involving large amounts of timestamped data, including DevOps monitoring, application metrics, IoT sensor data, and real-time analytics.
HoraeDB support InfluxDB v1.8 write and query API.
Warn: users need to add following config to server’s config in order to try InfluxDB write/query.
| |
Write
| |
Post payload is in InfluxDB line protocol format.
Measurement will be mapped to table in HoraeDB, and it will be created automatically in first write(Note: The default TTL is 7d, and points written exceed TTL will be discarded directly).
For example, when inserting data above, table below will be automatically created in HoraeDB:
| |
Note
- When InfluxDB writes data, the timestamp precision is nanosecond by default, HoraeDB only supports millisecond timestamp, user can specify the data precision by
precisionparameter, HoraeDB will automatically convert to millisecond precision internally. - Query string parameters such as
dbaren’t supported.
Query
| |
Query result is same with InfluxDB:
| |
Usage in Grafana
HoraeDB can be used as InfluxDB data source in Grafana.
- Select InfluxDB type when add data source
- Then input
http://{ip}:{5440}/influxdb/v1/in HTTP URL. For local deployment, URL is http://localhost:5440/influxdb/v1/ Save & test
Note
Query string parameters such as epoch, db, pretty aren’t supported.
5.2 - OpenTSDB
OpenTSDB is a distributed and scalable time series database based on HBase.
Write
HoraeDB follows the OpenTSDB put write protocol.
summary and detailed are not yet supported.
curl --location 'http://localhost:5440/opentsdb/api/put' \
--header 'Content-Type: application/json' \
-d '[{
"metric": "sys.cpu.nice",
"timestamp": 1692588459000,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
}
},
{
"metric": "sys.cpu.nice",
"timestamp": 1692588459000,
"value": 18,
"tags": {
"host": "web01"
}
}]'
'
Metric will be mapped to table in HoraeDB, and it will be created automatically in first write(Note: The default TTL is 7d, and points written exceed TTL will be discarded directly).
For example, when inserting data above, table below will be automatically created in HoraeDB:
CREATE TABLE `sys.cpu.nice`(
`tsid` uint64 NOT NULL,
`timestamp` timestamp NOT NULL,
`dc` string TAG,
`host` string TAG,
`value` bigint,
PRIMARY KEY(tsid, timestamp),
TIMESTAMP KEY(timestamp))
ENGINE = Analytic
WITH(arena_block_size = '2097152', compaction_strategy = 'default',
compression = 'ZSTD', enable_ttl = 'true', num_rows_per_row_group = '8192',
segment_duration = '2h', storage_format = 'AUTO', ttl = '7d',
update_mode = 'OVERWRITE', write_buffer_size = '33554432')
Query
OpenTSDB query protocol is not currently supported, tracking issue.
5.3 - Prometheus
Prometheus is a popular cloud-native monitoring tool that is widely adopted by organizations due to its scalability, reliability, and scalability. It is used to scrape metrics from cloud-native services, such as Kubernetes and OpenShift, and stores it in a time-series database. Prometheus is also easily extensible, allowing users to extend its features and capabilities with other databases.
HoraeDB can be used as a long-term storage solution for Prometheus. Both remote read and remote write API are supported.
Config
You can configure Prometheus to use HoraeDB as a remote storage by adding following lines to prometheus.yml:
| |
Each metric will be converted to one table in HoraeDB:
- labels are mapped to corresponding
stringtag column - timestamp of sample is mapped to a timestamp
timestmapcolumn - value of sample is mapped to a double
valuecolumn
For example, up metric below will be mapped to up table:
up{env="dev", instance="127.0.0.1:9090", job="prometheus-server"}
Its corresponding table in HoraeDB(Note: The TTL for creating a table is 7d, and points written exceed TTL will be discarded directly):
CREATE TABLE `up` (
`timestamp` timestamp NOT NULL,
`tsid` uint64 NOT NULL,
`env` string TAG,
`instance` string TAG,
`job` string TAG,
`value` double,
PRIMARY KEY (tsid, timestamp),
timestamp KEY (timestamp)
);
SELECT * FROM up;
| tsid | timestamp | env | instance | job | value |
|---|---|---|---|---|---|
| 12683162471309663278 | 1675824740880 | dev | 127.0.0.1:9090 | prometheus-server | 1 |